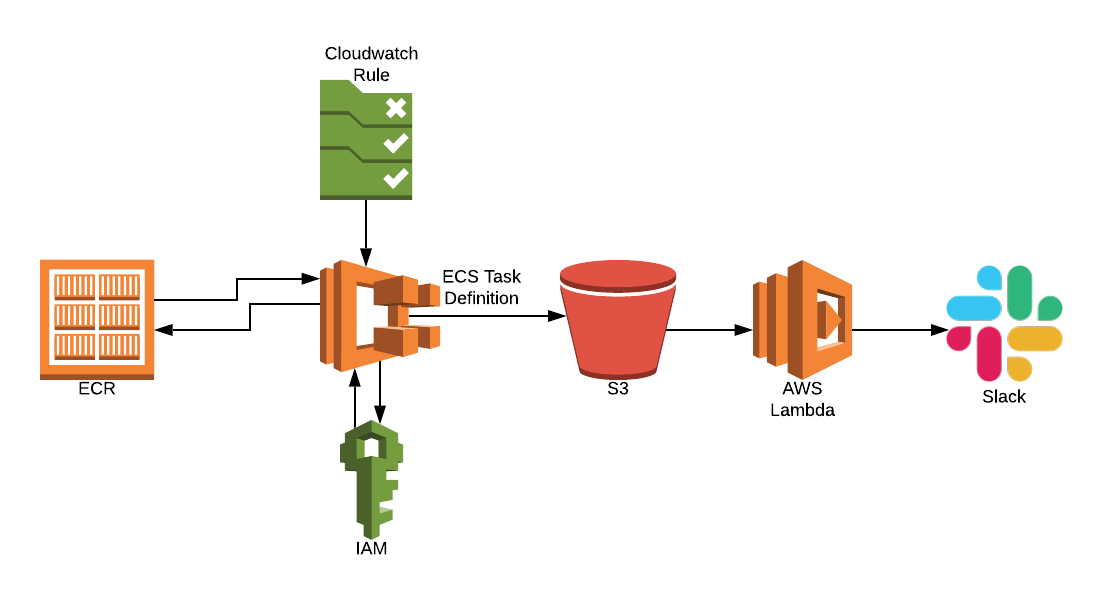
Getting started with Docker containers, and having a whale of a time
By Michael Pearce on February 13, 2020It’s time to dive into Docker!
This blog will be an introduction to getting started with Docker containers, and we’ll be walking you through…
? Building
? Tagging
? Running
? Testing and debugging
? Layers, caching, and benchmarking
? Use cases
? Cleaning up
Vision
By the end of this article, you’ll be able to add a Docker to your development toolset, enabling you to create, deploy, run, and test applications using containers. This should help you enhance your workflow by introducing consistency, isolation, and speed!
What is Docker?
Let’s start with the basics! Docker allows you to containerize a working environment, insert dependencies, automate setup, etc. You do this using structured files with standardized commands.
Getting started with Docker containers

Containers are a standardized unit of software. We package software into standardized units for development, shipment, and deployment.
One machine, such as a virtual server or even your laptop, may host multiple containers. Not to be mistaken with a ‘lightweight VM’, containers and virtual machines have similar resource isolation and allocation benefits. However, they function differently because containers virtualize the operating system instead of hardware. This makes containers are more portable and efficient.
Docker – what is it good for? ?
Absolutely nothing loads of things! Here are a few reasons why it’s so great:
Consistency
You may have heard the phrase “it works on my machine” a fair few times. Well, by scripting the instructions for building the image, we form some repeatability. If it works on my machine, it should work on yours too! Although this isn’t always that easy, as we can still get issues with discontinued package versions, dependencies, etc. There are some ways to assist with this, which we’ll cover later on.
Isolation
Docker allows you to isolate your application and the packages, dependencies etc. within the container, generally unaffected by the host machine. You should be able to run your app and test it the way it will later deploy on a production server, for example. This also provides some security benefits as a side product.
Automation
When your app is repeatable and isolated, a well-scripted environment is a lot easier to build and run autonomously minimal configuration. This often goes hand in hand with things like CI/CD (Continuous Integration and Development).
Speed
I’m sure you’re getting the point here, and how the previous points come together. Docker makes it simpler for developers and engineers to quickly create containerized applications that are ready to run. Managing, testing, and deploying them gets a much-welcomed speed boost with its efficiencies.
However…
It is often still hard to repeat.
From experience, I’ve had various frustrating issues rebuilding Docker images with versioning; usually of packages or libraries. I think this stems from the desire for consistency, prompting one to create an environment from a particular version of the base image. For example..
FROM ubuntu:17.10
…rather than just taking what is the latest at the time of build. The issue here is that ubuntu version 17.10 has reached the end of life and been discontinued, and therefore the repositories have been closed and withdrawn. When we try to run apt-get update, we cannot reach the repositories. We get 404 errors, and the build fails.
Err:8 http://security.ubuntu.com/ubuntu artful-security Release
404 Not Found [IP: 91.189.91.23 80]
Reading package lists…
E: The repository ‘http://archive.ubuntu.com/ubuntu artful Release’ does not have a Release file.
This is done purposefully by Ubuntu, and for a good reason – security. To avoid this happening so often, most popular operating systems have Long Term Support (LTS) options available for download and use.
A similar issue may occur when installing particular versions of packages or system libraries. If that package version was available with a repository from particular base image (operating system version) and that base image changes (it is discontinued, for example) the version of that package may not exist. You could just get the latest version of that package, but the code changes in that package may or may not work as expected when your app is run (think breaking changes!)
Networking can be challenging
A considerable contingent of the Docker community would say they consider networking with containers can be complex and confusing. Questions like “which Network Drivers I should use?”, “Single Host or Multi-Host Networking?”, and the issue of load balancing traffic via a proxy layer, and so on.
For a single non-production container you usually don’t have to worry too much, and when you’re getting started you probably won’t encounter the issues too soon. But, when you do, there are a few things that can help with these issues…
Upload/Download
Depending on your network connection, the time it takes to download and upload images can be frustrating, especially when you add more packages, code, etc., and the images get bigger in size and begin to take up more disk space. This can particularly affect things like application deployments (like in CI/CD) if it takes a long time to pull down either the base image for the build or the entire image itself. When you are building the image then pushing it back to a repository it is rare that your networks upload speed is the same as your download speed, it is almost always much slower!
Quick review
Docker provides a way to run applications securely isolated in a container, packaged with all its dependencies and libraries.
A container is a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another.
Build it
Start with a Dockerfile with some simple commands and structure.

The name of the file is simply Dockerfile. We have some instructions — FROM, RUN, ADD, ENV, CMD.
Most are quite self-explanatory:
FROM pulls another image, to use as a base.
RUN runs a command.
ADD adds files into the image.
ENV sets environment variables.
CMD sets the command to run when the container is started.
Instructions

Commands
There are graphical interfaces you can use to control Docker, but as a command-line advocate we want speed, right? I’m going to provide a few useful commands you can use.

Build it
Here is an example of a simple Docker build, giving the image a name and using the Dockerfile from the current working directory.

Result
We can use the Docker images command to see the result.

Note the repository name, the tag, image ID, created time, and size.
Tag
You saw the -t flag used there to identify the tag. I also mentioned ubuntu:17.10 earlier too; this is an example of a tag where ubuntu is the repository and 17.10 is the tag.
‘Latest’ is implied. If no tag is provided then the latest tag is added to imply that it is the latest build of that image.
We can have many versions (tags). You may give the same image multiple tags such as a version number, a date, or a development status. We can also use tags in the same way to identify different versions of the image. For example, I build an image and tag it myimage:1.0, then make some additions but this time when I build it I tag it myimage:2.0.
The format is like this –
<Image Name>:<Tag>
And you can also retag at image too!
docker <Image Name>:<Existing Tag> <Image Name>:<New Tag>
Building a base ?

This is a concept that often helps get around those versioning, or repeatability, problems that we considered earlier.
Build a Docker file with everything (but only what) you need, installing core packages etc., then push it to a repository to not be overwritten again. Most image repositories such as Dockerhub or AWS ECR have a feature to make images immutable.
Then, when you create any other new images, you use your base image as the base.
FROM mybaseimage:stable
This makes the base image predictable, rather than rebuilding and getting different package and library versions etc.
Run it
Running the image as a container generally depends on what your image does.
It might run a script that just returns ‘hello world.’

It might be a Linux-based container that you can pass in a command to run.

You might execute a command interactively and keep it going!

It might be something that starts up a local webserver or proxy so that you can view the result in a web browser.


Debug it
Rarely does any script, program, or application go as planned first time, so a key part of development is debugging. The good thing about the isolation Docker provides is that running the container image locally should produce the same result as running on someone else’s machine, or even a production server of some kind.
When you run the container image locally (on your computer) you get to see the standard output.

You can also use the Docker logs command to see system output, any console logging from your application etc.

You can find similar information with the Docker inspect command. You may even choose to run the container, and execute commands interactively in the running container to investigate.
See the example below where I’ve used the docker ps command to view the running Docker processes, then the docker exec command to run a bash shell in the running container. Then when I’m ‘in’ I can run Linux commands like the ls command to check all the expected files exist as part of the container image.

Layers
Like an onion, a Docker image is made up of many layers!
Let’s answer the question, “how does a Docker image work?” Each image consists of a series of layers. Docker makes use of union file systems to combine these layers into a single image. Union file systems allow files and directories of separate file systems, known as branches, to be transparently overlaid, forming a single coherent file system.
One step at a time
Watching the build process helps us to visualize those layers as each step is run to form the final image. Luckily I already had the `rocker/r-base` image stored locally on my file system, so the first step was quick.

Inspecting the build steps
Try not to cry while we start to peel the onion and look at the layers in the Docker image! We can use the docker history command to look at the layers that made up the image. Here is a simple example:

Here is quite an insightful view of the build steps for the popular python:3.6 image.

Caching
Image caching vs layer caching
Let us first separate the thinking between image caching and layer caching.
Layer caching
At each occurrence of a RUN command in the Dockerfile, Docker will create and commit a new layer to the image, which is just a set of tightly-coupled directories full of various file structures that comprise a Docker image.
During a new build, all of these file structures have to be created and written to disk – this is where Docker stores base images. Once created, the container (and subsequent new ones) will be stored in the folder in this same area.
This makes cache important. If the objects on the file system that Docker is about to produce are unchanged between builds, reusing a cache of a previous build on the host is a great time-saver. It makes building a new container really, really fast. None of those file structures have to be created and written to disk this time – the reference to them is sufficient to locate and reuse the previously built structures.
This is an order of magnitude faster than a fresh build. If you’re building many containers, this reduced build-time means getting that container into production costs less, as measured by compute time.
Image caching
The caching can be done to pull down a previous version of the image, then use that instead of rebuilding it all again. If the image exists locally on the system you can use the – cache-from flag to use that image as a cached version and avoid any rebuilding or pulling etc.
Beware: the cache-from flag will fail if the image is not found locally so you may need to put some logic in place to check.
Here is the one I made earlier…

Benchmarking
TLDR:
~50% difference in time to build images with either big long RUN commands or many small RUN commands
but with ~1gb size difference!*
*result from a quick benchmarking experiment, using a fairly large image (~5–6GB that usually took 40+ minutes to build.)
Speed vs size
When building and image with a Docker file, the more RUN, ADD and COPY commands you use, the more layers the image has when being created. This results in a larger image size, and longer initial build time. But it is more likely that so many of those steps will be affected by changes and will be rebuilt in subsequent builds.
However, by reducing the number of RUN commands, and grouping package install into one big command this takes less time to build (initial) and results in smaller image size. But one change to this long command would result in the whole thing being re-run when you need to change and rebuild the image.
When you using a cached Docker image (Docker pull the latest first, then Docker build — cache-from) updating a Dockerfile with many RUN commands is usually quicker because you only change one layer. Updating a Dockerfile that has one big RUN command takes longer because it only detects a difference in the command itself so re-installs all of the packages.
So, what I’m getting at, is that for base images (or images that generally don’t change frequently) we should use fewer RUN commands, and have more package installs, etc. together. Then we get a smaller image that is quicker to pull.
It is still worth having build caching in case of rebuilds. But be careful of chaining commands, with commands that would force a rebuild of that layer, e.g. installing packages and then cleaning up temp files are better off in separate layers.
For images that change frequently (and need to quick rebuilds) we should make sure we use build caching and use more RUN commands and keep each package/module installation to its own step/layer.
Use cases
Hopefully, you’ve started considering some use cases for getting started with Docker containers already. But, some simplified examples for inspiration may include…
Running jobs on Jenkins (or a similar automation server), making sure that your package versions, etc. are always as you expect and not impacted by changes in the system.
Creating and deploying visual and analytic dashboards. You can interact with other services such as data warehouses from your container, you can version control your code with git so others can collaborate, and hopefully running it locally should produce the same results as when it is hosted online!
Web applications or API endpoints are often hosted online and receive variable amounts of traffic. One of the many joys that cloud computing has brought is the ability to ‘auto-scale’ the amount of servers provisioned in and out to handle the traffic while staying cost-efficient. This, however, requires applications to be quick to deploy and repeatable.
Taking out the trash ?
When are done, we probably need to clean up! Docker images are notorious for sticking around and hogging disk space and running ports. Here are some useful commands, in order of general impact (low to high.)
docker stop <container id>
docker rmi <image id>
docker system prune
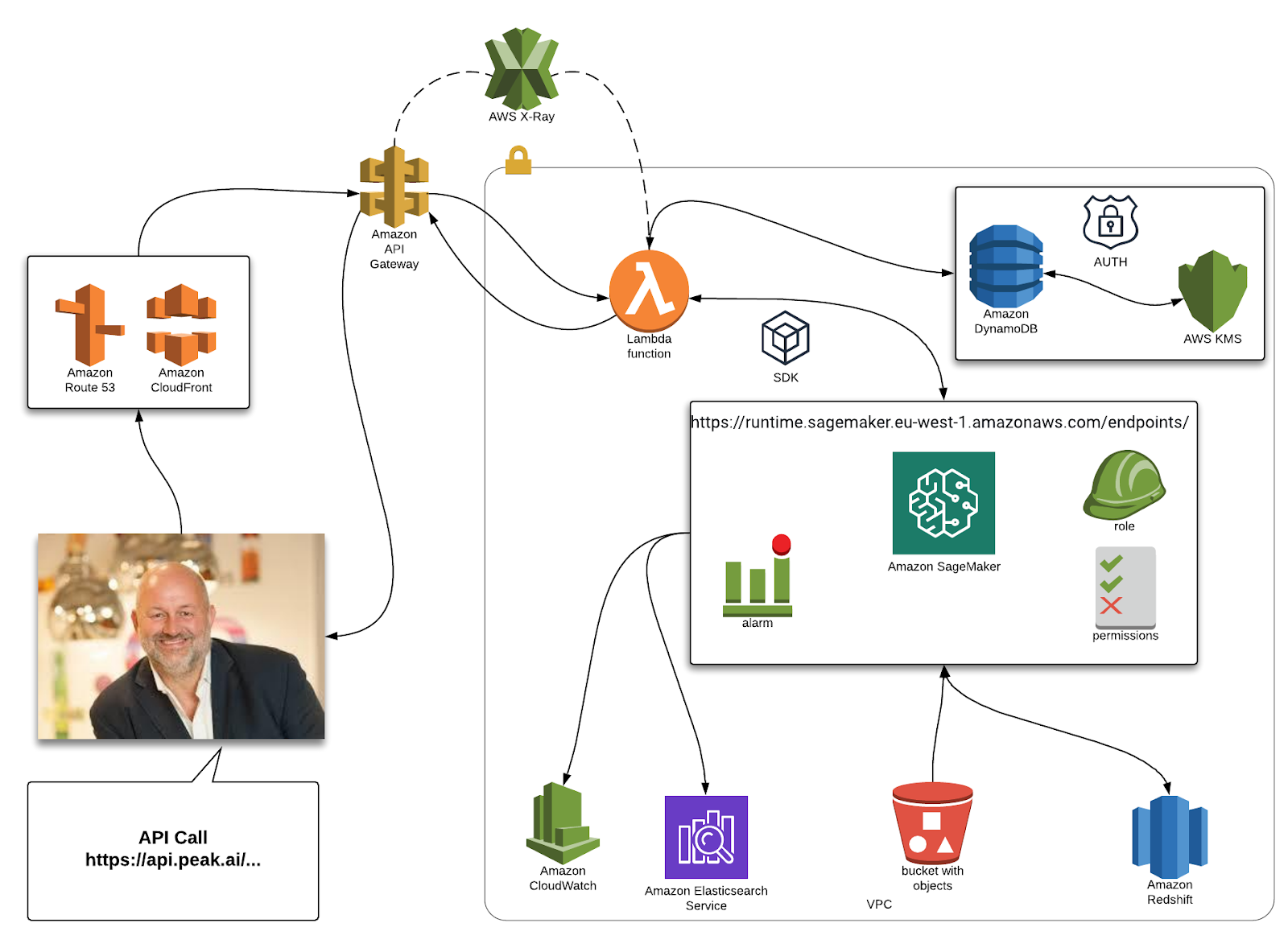
Sage advice – deploying machine learning models with Amazon SageMaker
Access key rotation: Converting a PoC to production-ready code